
Lo que escuchamos es una compleja combinación de fuentes de sonido y sus características inherentes interactuando con el entorno, ya sea interior o exterior, que luego decodifican nuestros oídos y cerebro. Ya hemos hablado de varios temas relacionados con altavoces y salas en artículos anteriores del blog (“La mejor forma de instalar tus altavoces en tu estudio casero', y 'Cómo ubicar correctamente un subwoofer en una sala”). Este artículo explora un aspecto concreto de la audición humana y cómo afecta a nuestra percepción del sonido.
¿Qué es el enmascaramiento sonoro?
Nuestros oídos trabajan en conjunción con nuestro cerebro para crear los sonidos que oímos en nuestra mente. Aunque ciertos fenómenos están relacionados directamente con los elementos de nuestro aparato auditivo (tímpano, huesos, cóclea, etc.), en nuestro cerebro se dan ciertos procesos mientras éste decodifica la información que recibe por los nervios auditivos. Uno de ellos se llama enmascaramiento sonoro y es interesante por la forma en que puede alterar nuestra percepción del sonido.
El enmascaramiento sonoro se da cuando la percepción de un sonido se ve afectada y comprometida por la presencia de otro sonido. El enmascaramiento sonoro en el dominio de la frecuencia se denomina enmascaramiento simultáneo, enmascaramiento de frecuencia o enmascaramiento espectral. El enmascaramiento sonoro en el dominio del tiempo se conoce como enmascaramiento temporal o enmascaramiento no simultáneo. En este artículo nos centraremos en el enmascaramiento simultáneo, que ocurre cuando una señal, es decir, el sonido que queremos oír, se ve comprometido por un enmascaramiento sonoro que se da al mismo tiempo.
Umbral de enmascaramiento
Ahora veamos qué es el umbral de enmascaramiento. En primer lugar, el umbral sin enmascarar define el nivel más bajo de una señal que podemos percibir sin que haya una señal enmascarada presente. El umbral de enmascaramiento es el nivel más bajo de la señal percibida cuando se combina con un sonido enmascarado concreto.
La cantidad de enmascaramiento es la diferencia entre el umbral de enmascaramiento y el umbral sin enmascarar. Por ejemplo, si el umbral sin enmascarar es de 20 dB y el umbral de enmascaramiento es de 36 dB, la cantidad de enmascaramiento será de 16 dB.
El test básico de enmascaramiento auditivo mide los umbrales sin enmascarar en una persona. A continuación, se introduce un ruido de enmascaramiento a un nivel de presión sonora fijo mientras se reproduce la señal inicial. El nivel de la señal inicial varía hasta que se mide el nuevo umbral, definiendo así el umbral de enmascaramiento.
Enmascaramiento simultáneo de frecuencias similares
El enmascaramiento simultáneo se da cuando un sonido se hace inaudible debido a un ruido, o enmascarador, con la misma duración del sonido original. La efectividad del enmascarador al subir el umbral del sonido original dependerá de la frecuencia de este sonido y de la frecuencia del enmascarador.
El mayor nivel de enmascaramiento se da cuando el enmascarador y el sonido están en la misma frecuencia, y este efecto disminuye a medida que la frecuencia de sonido se aleja de la frecuencia del enmascarador. Este fenómeno se denomina enmascaramiento de frecuencia y se da porque el enmascarador y el sonido original están dentro del mismo filtro auditivo, lo que significa que la persona que percibe el sonido no puede distinguirlos, pues se perciben como una única señal.
La imagen 1 de debajo muestra el fenómeno del enmascaramiento simultáneo utilizando un tono de enmascaramiento centrado en 410 Hz. Notarás que los patrones de enmascaramiento cambian según la intensidad del enmascarador. A niveles bajos, con sonidos de enmascarador de 20 a 40 dB, los patrones de enmascaramiento no afectan mucho a nuestra capacidad de escucha. A medida que aumenta la intensidad del enmascarador (de 50 a 80 dB), las curvas de enmascaramiento se amplían, especialmente en los sonidos con frecuencias más altas que el enmascarador. Esto recibe el nombre de “expansión hacia arriba del enmascaramiento” y es el motivo por el cual los sonidos que interfieren enmascaran más las señales de alta frecuencia que de baja frecuencia.
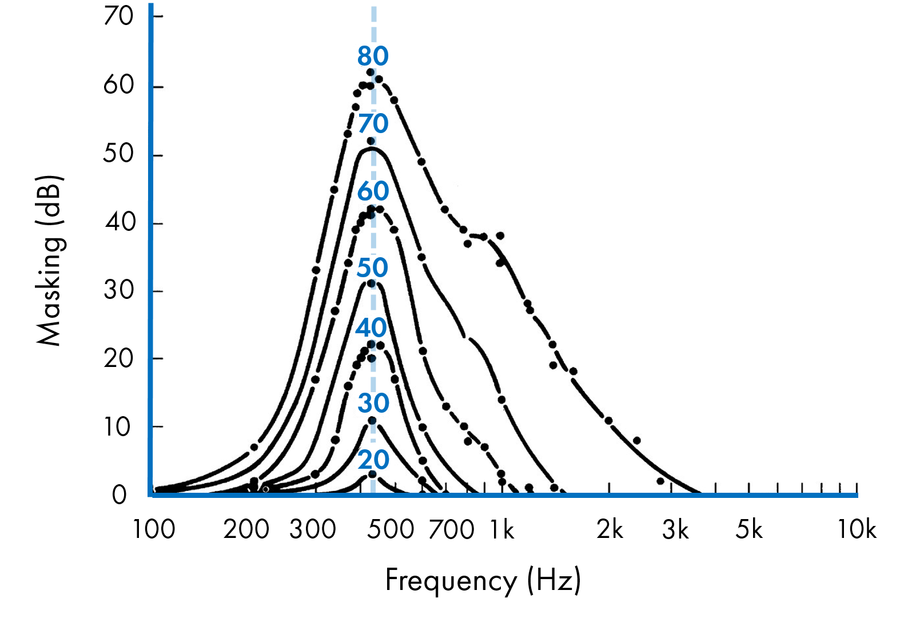
Enmascaramiento en las frecuencias bajas
Ahora, si repetimos el experimento utilizando un tono de enmascaramiento a 150 Hz, el resultado es una expansión hacia arriba más amplia en las frecuencias altas. El fenómeno de enmascaramiento sonoro se hace más fuerte y se extiende más a lo largo del espectro de sonido.
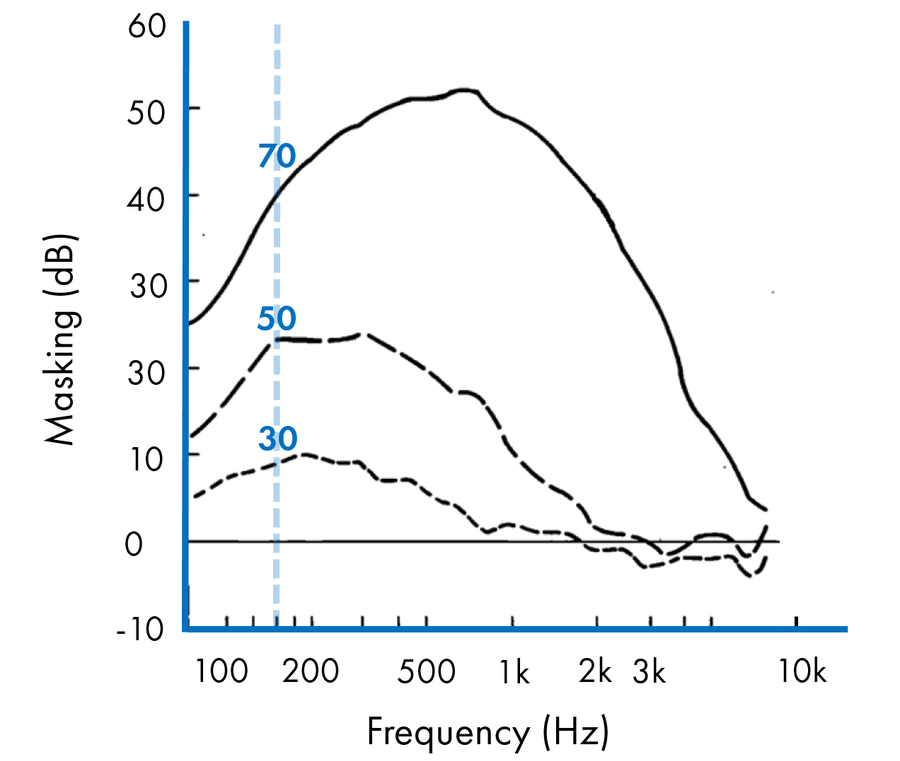
Alteración de la percepción subjetiva del sonido
Exploremos ahora cómo afecta el enmascaramiento auditivo a nuestra percepción del sonido en altavoces y subwoofers. Con los ejemplos y gráficos anteriores, podemos prever que si los niveles de reproducción son muy altos en las frecuencias graves y medias-graves, habrá enmascaramiento auditivo, comprometiendo nuestra percepción auditiva principalmente en el espectro que está por encima de los tonos de enmascaramiento.
En cualquier sistema de megafonía, si el subwoofer reproduce, tanto en interiores como en exteriores, un nivel excesivo de graves, subjetivamente el espectro de medios graves parecerá poco claro, poco definido, y con falta de claridad y dinámica. Todo el contenido musical sobre, por ejemplo, una octava de medios-graves, parecerá poco definido e impreciso. Si el nivel de ciertos instrumentos parece demasiado bajo, la mezcla ya no estará equilibrada. El enmascaramiento sonoro se dará independientemente del diseño y la calidad del altavoz o subwoofer. El oído y el cerebro pierden parte de la información en el espectro de los medios-graves.
De forma similar, el mismo fenómeno ocurre con un solo altavoz colocado, por ejemplo, en la esquina de una sala, cerca de dos paredes sin atenuación alguna para los graves. Los límites de la sala cambiarán el espacio de radiación del altavoz y producirá un aumento de los graves de hasta 12 dB por debajo de los 200 Hz en la respuesta del altavoz. Eso es un nivel adicional considerable, y también reducirá la percepción de sonido en el espectro de los medios-graves.
Minimizar el enmascaramiento sonoro
Hay muchas situaciones en las que se reproduce una cantidad excesiva de graves, lo que da lugar a una percepción musical y del sonido alterada. Pero ¿cómo se puede evitar? La respuesta es bastante sencilla.
Reducir la cantidad excesiva de frecuencias graves en la mezcla o directamente en el sistema de megafonía puede parecer frustrante al principio, pues parecerá que los graves no destacan tanto. Sin embargo, el beneficio de hacerlo es inmediato en la definición y claridad del sonido en el rango medio y medio-grave del espectro. El objetivo es encontrar el equilibrio perfecto, como con todo.
¿Cómo se reducen los niveles excesivos de graves? Una opción es ajustando el balance de la mezcla de sonido (en la salida principal del mezclador). Si el contenido está pregrabado, esto no es posible y básicamente hay que ajustar el sistema de megafonía. La Serie K.2 de altavoces QSC y la Serie KS de subwoofers cuentan con un ecualizador integrado que permite configurar fácilmente un filtro shelving por debajo de los 200 Hz, por ejemplo. Estos ecualizadores son sencillos y fáciles de utilizar, configurar y guardar en la memoria interna del altavoz en una “escena” de usuario, que se podrá recuperar en cualquier momento cuando haga falta.
Además, los mezcladores TouchMix de QSC ofrecen todas las funciones necesarias para ajustar sus salidas principales y auxiliares utilizando parámetros de ecualización comunes.
Conclusión
Cuando se reproduce un contenido excesivo de frecuencias graves a través del sistema de megafonía, se producirá el fenómeno de enmascaramiento sonoro, lo que perjudica la percepción del sonido. Para recuperar la definición, claridad y equilibro del audio, es necesario reducir el nivel de algunas frecuencias graves. Al hacerlo, todos los elementos de la mezcla volverán a estar equilibrados y transmitirán un sonido tridimensional correcto. Recuerda que lo que escuchamos es la compleja combinación e interacción de la fuente de sonido, el entorno en el que nos encontramos y la forma en que nuestro oído y cerebro decodifican el sonido. Por ello es de gran utilidad entender los puntos fuertes y débiles de cada elemento de la cadena. ¡Feliz escucha!
Referencias
[1] Egan, J.P. and H.W. Hake, On the masking pattern of a simple auditory stimulus. The Journal of the Acoustical Society of America, 1950. 22(5): p. 622-630.
[2] Tobias, J.V., Low‐frequency masking patterns. The Journal of the Acoustical Society of America, 1977. 61(2): p. 571-575.
Christophe Anet
Latest posts by Christophe Anet (see all)
- History, Development and Applications of Column Loudspeakers - May 30, 2025
- Why is Dynamic Range so important? - May 30, 2023
- Differences between Flown and Floor-Mounted Subwoofer Deployments - May 2, 2023